CREATE PIPELINE
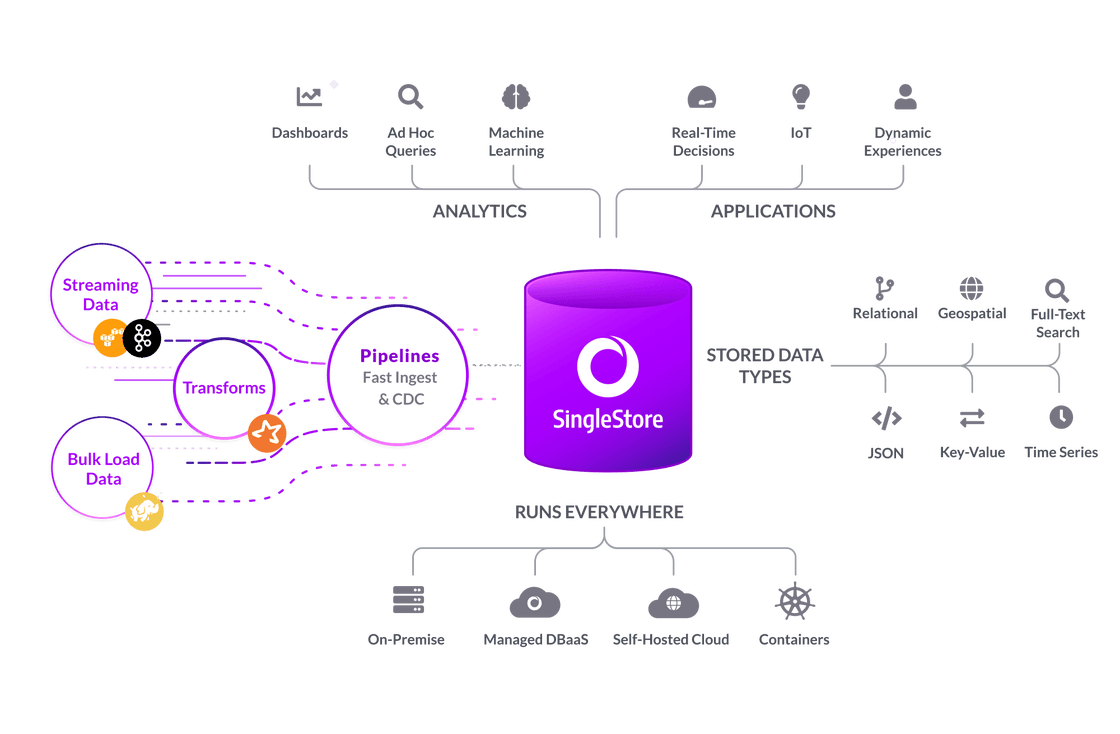
Effortlessly set up streaming ingest feeds from Apache Kafka, Amazon S3, and HDFS using a single CREATE PIPELINE command
Extract
Pull data directly from Apache Kafka, Amazon S3, Azure Blob, or HDFS with no additional middleware required
Transform
Map and enrich data with user-defined or Apache Spark transformations for real-time scoring, cleaning and de-duplication
Load
Guarantee message delivery and eliminate duplicate or incomplete stream data for accurate reporting and analysis
Rapid Parallel Loading
Load multiple data feeds into a single database using scalable parallel ingestionLive De-Duplication
Eliminate duplicate records at the time of ingestion for real-time data cleansingSimplified Architecture
Reduce or eliminate costly middleware tools and processing with direct ingest from message brokers
Exactly Once Semantics
Ensure accurate delivery of every message for reporting and analysis of enterprise critical dataBuilt-in Management
Connect, add transformations and monitor performance using intuitive web UIBuild Your Own
Add custom connectivity using an extensible plug-in framework
Test drive SingleStore
Enjoy the ultra-high performance and elastic scalability of SingleStore.